Neural Networks in Market Research
How They Change The Rules of The Game.

Similar cases:
Conversational ResearchConversational Research EvolutionBy now, ChatGPT managed to make a lot of noise. OpenAI has lowered the barrier to entry into AI technologies to the level of “if you know how to use the chat – go ahead, have fun.” Users were simultaneously impressed and frightened by the illusion of a deep understanding of whatever the chat was fed, the high speed of processing material of any complexity, and its variability. People instantly realised that AI could easily do the jobs that many of them were paid to do.
Programmers’ biggest fear is being replaced by a program. Strong AI has brought this prospect closer: some large language models (LLMs) already write good enough code. Let’s use an analogy to understand that researchers are not very different from programmers.
Here is a simple problem that even a junior student can solve:
“Sort the numbers in descending order: 2, 8, 1, 4, 6, 3, 5, 9, 7.”
In order for a machine to solve this task, a specially trained person is needed – a programmer who a) reads the problem, b) comes up with an algorithm, c) writes code in the language of the machine. For example, in Fortran:
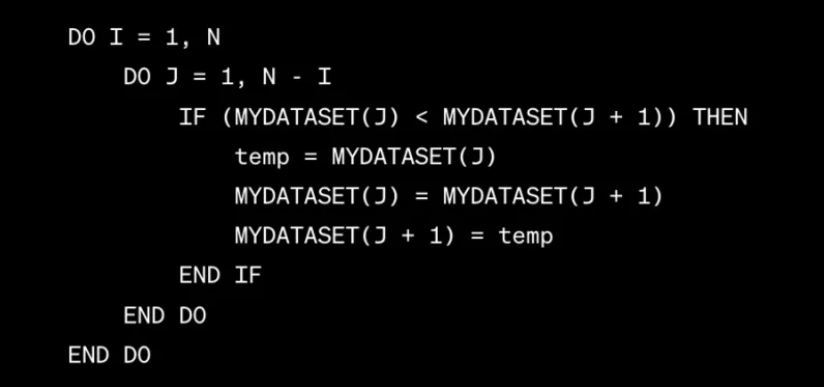
Now let’s consider a simple research problem:
“Brand XXX is entering a new market. The business is localising and must change its name. It is important to ensure continuity and not lose current brand users. The task is to choose the best of five options for a new name.”
The client cannot come up with an algorithm for solving the problem, but they can explain what they need. At this point, you will need another specially trained person – a researcher who will:
a) read the client’s problem,
b) come up with a solution algorithm using research methods and tools,
c) provide the client with information for making a business decision in the form of a report.
The researcher is a kind of “interface” for the client’s access to research tools. The “interface” accepts a task from the client in the form of text and gives them an answer – again, in text. It turns out that text, language, is the most powerful of researchers’ tools. Researchers use language to perform each and every task.
Working in ChatGPT is similar to programming in simple human language. Instead of code, we use prompts – a set of arbitrary instructions about how AI should behave and what it should do. A prompt cannot be specified to just any length, it has to adhere to the limitations of the LLM model. In our experiments (which we will describe below) we used gpt-3.5-turbo and a “smarter” version of gpt-4, as well as free open-source models (gpt4all-j 1.3, BLOOMChat-176B, MPT-7B). The listed LLM models understand complex texts well and provide (seemingly meaningful) answers.
What then is the fundamental indispensability of the human researcher? Let’s try to take everything “human” out of the standard research process and take a closer look at where we end up.
Stage 1. Statement of the research problem
This is one of the most painful stages that affects the success of the study. The researcher often needs several working days of long correspondence by email in order to process the initial brief and extract from it a clear statement of the results that the client actually needs.Here is an example of a fuzzy, unclear request to a research agency:
Category – natural food products for animals. Manufacturer of organic food and vitamin supplements for cats and dogs. Target audience – owners of cats and dogs aged 18 to 65 years. These are divided into:
– those who already use natural and organic products to feed their pets;
– those who use standard pet food, but are interested in healthier alternatives and are willing to consider switching to natural products;
– those who have not thought about replacing food, but are open to information about the benefits of natural nutrition for their pets.The task is to test hypotheses and insights for future positioning.
The phrase “test hypotheses and insights” is particularly unclear here. Testing is about quantitative methods, surveys; but we usually get insights at the qualitative stage, and the client didn’t mention anything about that at all. Our manager needed 3 iterations of correspondence to clarify the brief.
How can we get AI to do this job for us? For example, we could write the following prompt:
Analyze the client’s research brief. Determine whether it can be used to pinpoint the business challenges faced by the client. The business objective answers the questions: why is the client conducting this research? What decisions should be made based on the research results? Use the following classifier of business objectives and associated key research results: .
Client brief:
So, what we did in the prompt:
clearly set the task for the neural network,
provided a methodological framework to work within,
provided the client’s request, as-is.
What answer did the model give us?
Judging by the brief presented, the client’s business objective has not yet been clearly defined. They say that they want to “test hypotheses and insights for future positioning,” but do not indicate which specific hypotheses they want to test or what exactly they expect to see in the final result of the study. However, it can be assumed that the client’s tasks can be associated with two types of business objectives from the proposed classifier:
1 Business objective: Come up with something new, find points of growth or optimisation
Research results: People’s needs, Peculiarities of human behavior, Product ideas.
This type of task may be related to the client’s desire to find new growth areas for their brand, identify new product ideas, or improve current positioning.
2 Business objective: Decide “to do or not to do” something, “to continue or not”, “what to prioritise”
Research results: Good/bad rating, Ranked list, Improvement ideas
The client may be looking to determine whether they should continue to focus on natural and organic animal nutrition products, how this is perceived by their target audience, and how this might impact their business.
However, more information from the client is needed to more accurately define the business objectives and research questions that will be used in the survey. For example, which hypotheses they want to test, which aspects of “future positioning” interest them, and what kind of results they expect to receive from the research.
Like our manager, the neural network figured out what information was missing in the request. More clearly than the manager, it formulated possible situations and expected results. Imagine how the customer experience and speed would change if, instead of reading three letters from the manager, they simply had to choose: do you want to get something similar to No. 1 or No. 2 in the results?
Stage 2. Development of tools
Let’s assume that the client said “We want to get No. 1 – the needs of people, the characteristics of their behavior, their attitude towards our idea.” We can automate the decision of choosing which methodology to use. Great – so, we feed the model the following prompt:The client said that their objective is option 1. Write a list of questions for a qualitative interview guide to solve the client’s problem.
What did the model say?
Based on business task No. 1 (“Invent something new, find points of growth or optimization”), we can propose the following list of questions for a qualitative interview guide:
1) Tell us how you feed your pet. What is important to you when choosing food?2) Do you use natural or organic products to feed your pet? If yes, why did you make this choice? If not, why not?
3) What do you like or dislike about natural or organic foods for your pet?
4) What would convince you to switch to natural or organic products if you don’t already use them?
5) How does information about the composition and origin of food influence your choice? How do you verify the accuracy of this information?
6) Have you noticed any changes in your pet’s health or behavior since switching to natural or organic products?
7) What additives or food ingredients are most important for your pet’s health?
8) What would you like to see in the ideal food for your pet?
9) What challenges have you encountered in switching to natural or organic foods for your pet?
10) If you could suggest an improvement for natural or organic pet food products, what would it be?**These questions will help you better understand the needs of the client’s target audience, the nuances of their behavior, and generate product ideas to optimise the current offer or create new products.
This is a good result. But what is qualitative research without audience selection? Let’s remember the client’s description: “Owners of cats and dogs aged 18 to 65 years. Inside they are divided into: those who already use natural and organic products to feed their pets; those who use standard food, but are interested in healthier alternatives and are willing to consider switching to natural products; those who have not thought about replacing food, but are open to information about the benefits of natural nutrition for their pets.”
The approach to audience selection may vary. Typically, this is done through a recruiting questionnaire. We give the model a prompt along with examples of similar questionnaires from our experience:
Using the template below, create a list of questions for the screener. Make sure that the questions check all the criteria from the description of the target audience, but do not add unnecessary questions. Try to avoid “yes-no” questions. Sample screener:
The model copes with this swiftly and simply:
Your screener might look like this:S1. What age are you? Please enter a number.
If S1 < 18 or S1 > 65 – end the interviewS2. Are you the owner of a cat, a dog, or both?
/One answer/
– I am a cat owner
– I am a dog owner
– I am the owner of both cats and dogs
– I am not the owner of either a cat or a dog.If S2 = 4 – end the interview
S3. What type of food are you currently using for your pet?
/One answer/
– Standard food from the store
– Natural and organic products
– Both standard food and natural products
– Another type of food
– I find it difficult to answerS4. How do you feel about the possibility of switching to natural products to feed your pet?
/One answer/
– I already use natural products to feed my pet.
– I don’t use natural products, but I’m willing to consider this possibility
– I have not thought about changing food, but I am open to information about the benefits of natural food for my pet
– I’m not considering switching to natural products- I find it difficult to answerIfS4 = 4 – end the interview
The model not only set the necessary qualifying conditions and filters but also divided the target audience into segments in accordance with the client’s description. You can immediately ask it to provide an answer in xml script format, which we use to prepare the electronic questionnaire. By providing the model with examples from past projects, we get the following:
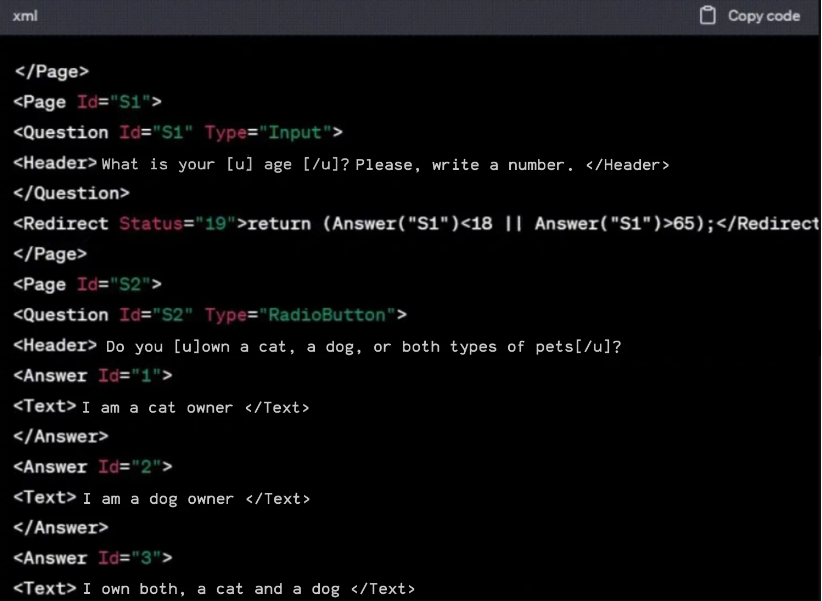
A trained eye will notice that the model even placed “semantic emphasis” in the wording with tags ([u]…[/u]), that is, it proved to be more caring than the average processor. In general, our toolkit is ready.
Stage 3. Data collection
ChatGPT is designed to communicate with people, understand their instructions, and generate responses based on them. But it’s not so easy to make a “cookie-cutter” model do the opposite – want something from a person. We had to do some heavy lifting to get the model to follow the guide without making the respondents doubt its level of awareness: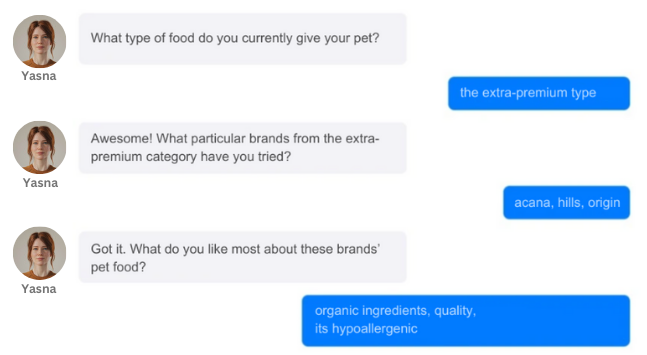
How do respondents react to such communication? Is it possible to get a real high-quality answer in this format, like in an in-depth interview? We experimented with different audiences and tasks. Now let’s try to communicate with hard-to-reach youth on the topic of sports clothing.
To the open question “In what situations do you wear sportswear?” in a standard questionnaire we get an average of 22 characters per line. Our auto-moderator asks three questions instead of one: the respondent sees the original question plus two “probing” questions, the content of which depends on the respondent’s answers. Our experiments show that the quality of the answer with probing increases nonlinearly: respondents write not 3 but 7 (!) times more text – 151 characters on average.
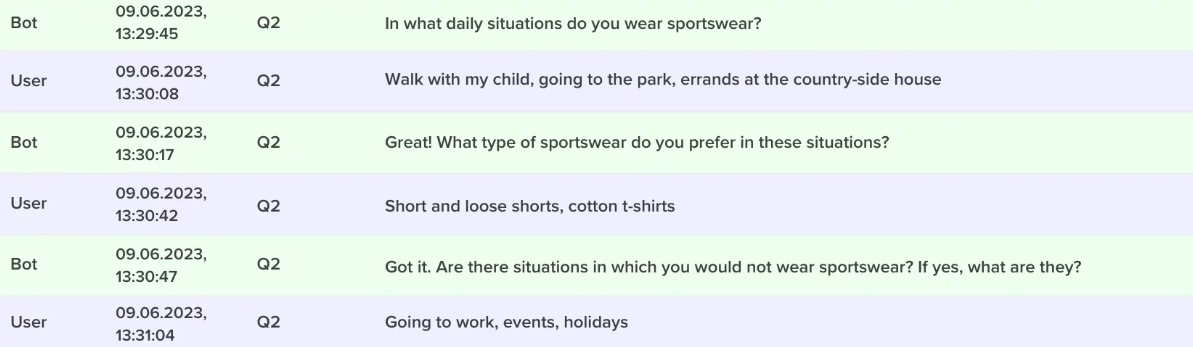
This is achieved through a more human attitude towards the respondents: our auto-moderator is friendly, empathetic, and lives in the chat that everyone is familiar with. Of course, we are still a long way from achieving qualitative data depth.
Stage 4. Data processing
The correspondence between a respondent and auto-moderator is not exactly light reading. Fortunately, LLM easily copes with the task of creating a summary of the interview so that it turns out something like this:“I wear sportswear in everyday situations, such as walking with my child, going to the park and doing errands at my country-side house. In such cases, I prefer to wear short and loose shorts and cotton T-shirts. However, I don’t wear sportswear to work or for events and holidays.”
Searching for insights in this format is much easier. But what if we have a quantitative task? 50 full interviews = approximately 50 pages of unstructured text. A lot of information and work for an experienced coder.
With LLM we will process this ten times faster. One interview with 10 questions is an ideal “chunk” of 1000-1500 words. It successfully fits into a model that picks out individual semantic units from the content:

The last point about “driving in the car” is something that the respondent indirectly mentioned in another part of the transcript:
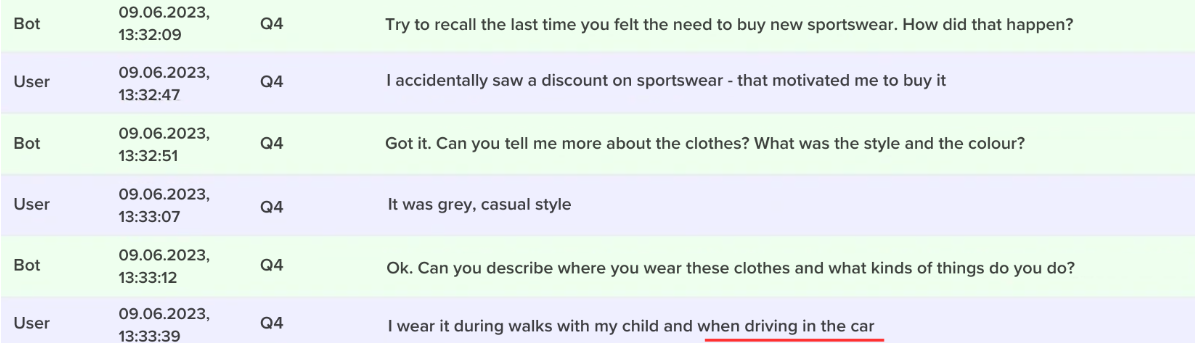
So, with a simple coding algorithm, we can turn qualitative data into quantitative data. This opens up a path to a new research type that combines all methods’ advantages.
Stage 5. Analysis
Our imagination + LLM capabilities allow us to ponder our dream system for generating insights and – instantly! – their verification. Imagine that you have an interface that runs in human language. You tell it:”Find all the answers to the question: “How do people imagine an ideal country?” Group them into categories. Illustrate each answer with quotes.
We get:
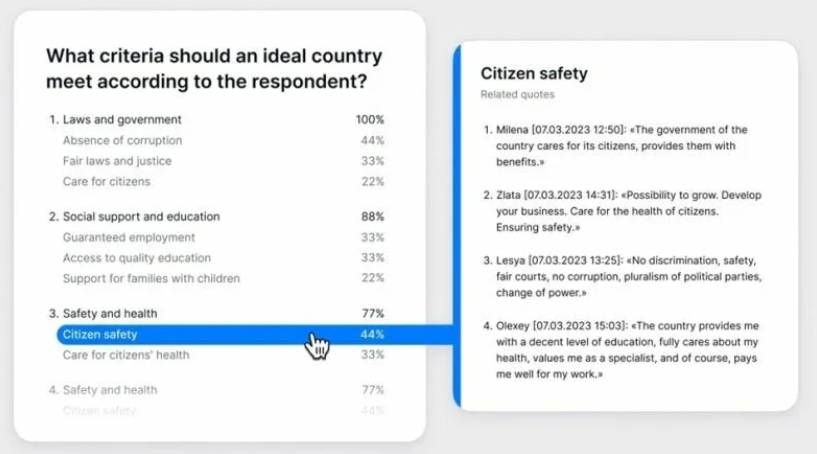
For now, this layout was created by our designers. But the data it presents is real – we got it through a step-by-step interaction with the GPT-3.5 API:
– received a list of answers to the question in the first transcript, wrote down quotes;
– found which answers from the list were in the next transcript, and wrote down the quotes;
– found answers that were not mentioned earlier, wrote them down along with the quotes;
– and so on for each subsequent interview.This is the most basic version of qualitative-quantitative analysis.
Nothing prevents us from going even further in our thought experiment. Theoretically, the role of the researcher in this process can be reduced to a task setter: “Based on , give recommendations on what the client should do, guided by the following .” If these same “action standards” are on the system side, you could remove the “researcher” figure entirely and let the client interact with the data in its raw form. However, by the time such a system is created, we cannot be sure that, on the client side, there will still be a human being to perform the interaction.
Recording
Conversational Research Basics: Essentials and Applications
WORKSHOP: Learn more about Conversational Research.
Learn more
Continue reading
Top picks about AI-powered interviewing

